Posted on: May 20th 2026
1. Introduction: The QA Paradox in AI Publishing
If you have worked in journal production or editorial operations, QA usually follows a familiar rhythm. A workflow runs, something breaks, the team isolates the issue, fixes the rule, and reruns the process. If the output stabilizes, the problem is considered solved.
That rhythm depends on repeatability.
AI disrupts that rhythm almost immediately.
The same system that formats manuscripts may now generate summaries, suggest reviewers, or enrich metadata. Run the same task twice and the outputs are not always identical. The differences are often subtle, but they can change tone, emphasis, or interpretation.
Nothing is technically wrong, yet something feels less certain.
AI systems are designed to interpret and generate rather than execute fixed instructions. That means variation is expected, not exceptional.
This creates a different kind of QA problem, especially in the context of AI quality assurance in publishing where traditional validation methods no longer apply. Instead of checking whether outputs match expectations, teams are deciding whether outputs can be trusted. This is where QA for AI agentsbegins to diverge from conventional software testing.
In publishing, where accuracy, traceability, and compliance are essential, that shift is significant.
2. Why Traditional QA Fails for Non-Deterministic AI Systems
Traditional QA assumes control. A defined input produces a defined output, and validation confirms alignment.
AI systems do not behave that way.
They produce outputs based on probability. Small differences in input can lead to different responses, and more than one version may be acceptable. This makes it difficult to define a single correct output.
This is why organizations are moving toward QA frameworks for non-deterministic AI, where validation is based on probability, coverage, and risk rather than fixed outputs.
In publishing workflows, this becomes visible quickly. A summary may highlight different sections of a paper depending on how the model interprets it. Citation suggestions may be relevant but inconsistent. Metadata tagging may vary based on context.
The more difficult issue is subtle error. A slightly incorrect reference or an unsupported claim can appear credible. These are not obvious failures. They often pass initial checks and surface later. Research has shown how easily such outputs blend into legitimate content.
At that point, QA becomes less mechanical.
Teams are no longer asking whether something is correct. They are asking whether it is reliable enough to publish. These challenges are driving the adoption of probabilistic AI testing frameworks that focus on behavior patterns instead of deterministic correctness.
Exhibit 1. How QA Logic Changes with AI
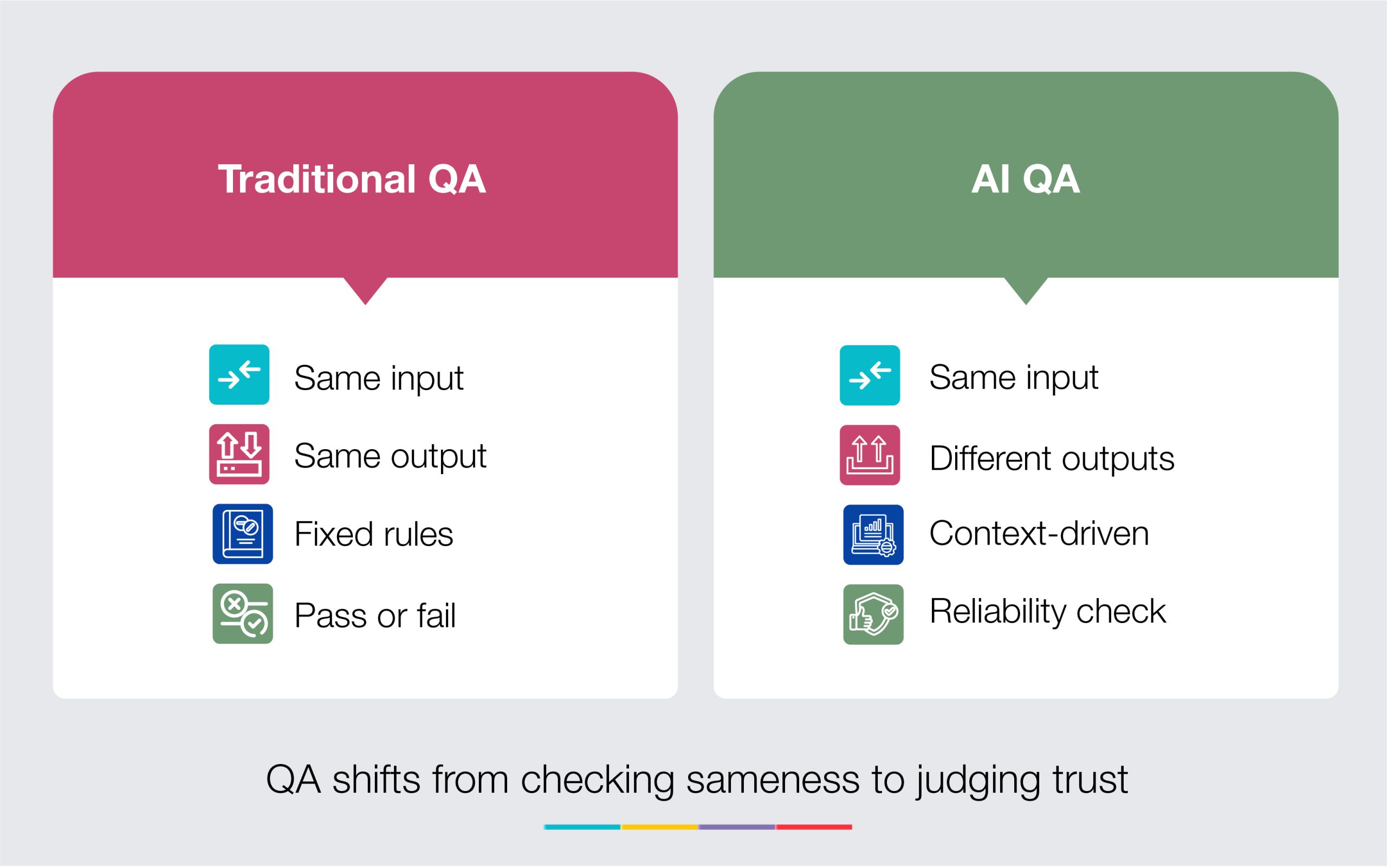
This shift explains why QA feels less certain. The system is not failing. It is behaving differently, and that difference requires interpretation.
3. Defining Quality for AI in Publishing
Once outputs vary, quality becomes less absolute.
Teams begin to rely on a set of signals. Is the content accurate? Does the system behave consistently? Can outputs be traced when needed? Is there enough visibility to understand how a result was produced?
These questions reflect how publishing actually operates. Accuracy, citation integrity, and compliance remain essential. Industry guidance continues to reinforce that these standards do not change with AI adoption.
Over time, reliability becomes the anchor.
Outputs do not need to be identical, but they must remain within acceptable limits. Teams build confidence not from precision, but from predictable behavior within those limits. These dimensions directly influence AI agent output reliability, which is becoming a key benchmark in publishing workflows.
This shift is central to improving AI reliability in publishing environments, where consistency and traceability matter as much as accuracy.
Quality becomes less about perfection and more about trust.
4. Core Pillars of AI QA Frameworks
Once variability is accepted, QA shifts toward managing it. These pillars form the foundation of modern AI agent quality control frameworks in publishing.
Validation becomes layered. Teams check structure, meaning, and domain alignment together. Grounding outputs in verified sources reduces the risk of incorrect or fabricated content. This is where LLM output validation becomes critical, ensuring outputs meet structural, semantic, and domain-specific expectations.
Testing expands beyond fixed cases. Teams use variations, edge scenarios, and imperfect inputs. This reveals how systems behave under realistic conditions rather than ideal ones. These approaches align with validation strategies for probabilistic systems, where coverage matters more than repetition.
Traceability becomes essential. Teams log prompts, outputs, and model versions. When something goes wrong, this record allows them to understand what happened and respond effectively. This enables structured auditability for LLMs, which is essential for compliance and reproducibility in publishing.
Human review becomes more focused. Editors do not review everything. They concentrate on outputs that feel uncertain or high-risk. Experience becomes more important than volume.
Exhibit 2. How QA Decisions Are Made Today
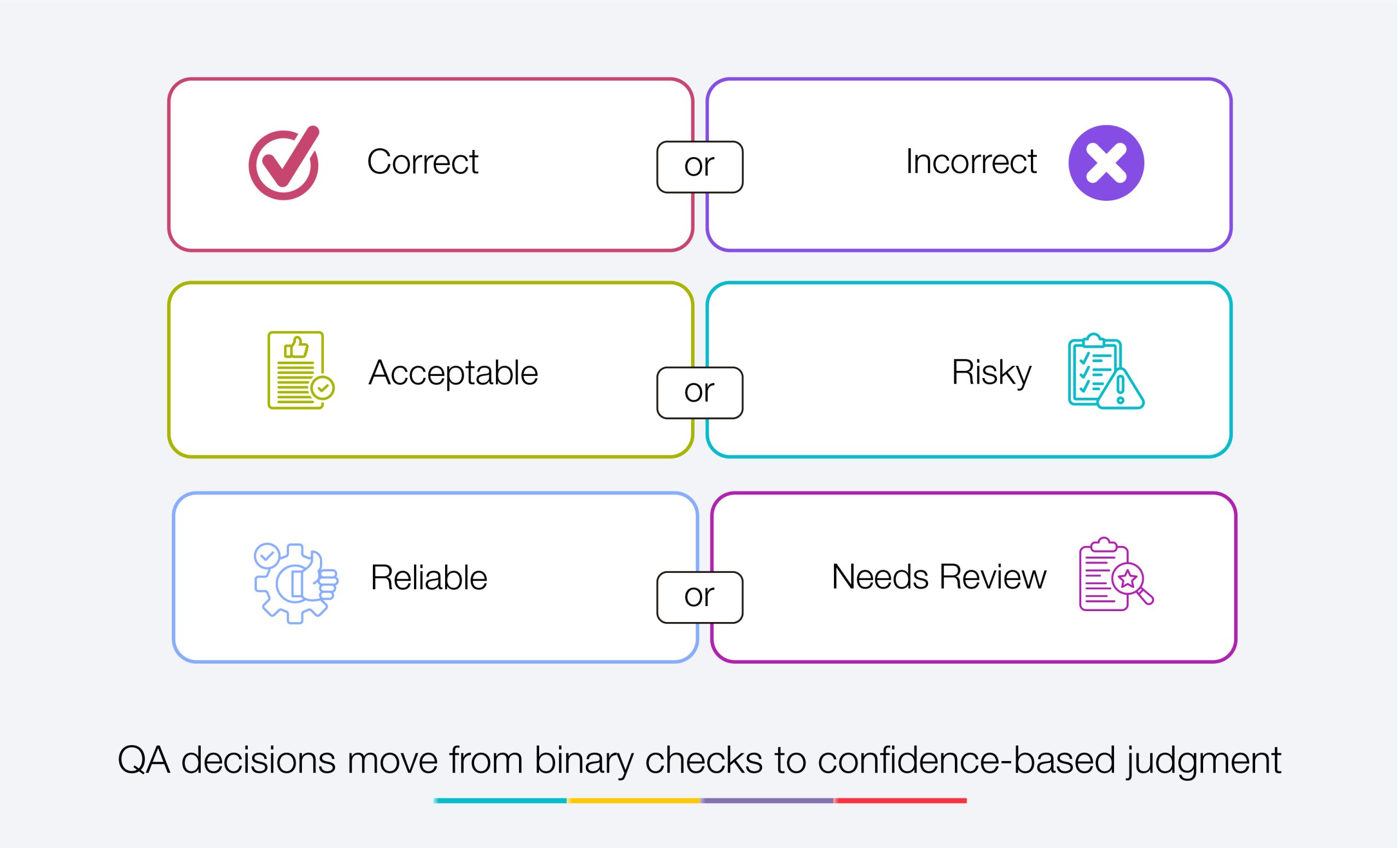
Continuity becomes the final piece. AI systems evolve, and outputs shift over time. Monitoring allows teams to detect drift early and maintain stability. Continuous monitoring strengthens AI agent quality control, allowing teams to maintain performance over time.
These practices do not remove variability. They keep it within control.
5. Validation Frameworks for Generative AI in Publishing
In practice, validation no longer sits at the end of a workflow.
It starts earlier than expected. These approaches form the basis of validation frameworks for generative AI in publishing.
Prompt design has a direct impact on output stability. Clear prompts reduce variation. Vague prompts introduce unpredictability.
During generation, constraints help guide outputs. Grounding responses in reliable sources is especially important for citations and factual content.
After generation, automated tools handle structure, formatting, and reference checks. Infrastructure such as Crossref supports citation validation. Human reviewers then assess context, tone, and alignment with editorial expectations.
Such frameworks are increasingly important for AI testing in scholarly publishing, where factual accuracy and citation integrity are critical.
Exhibit 3. Where Validation Happens
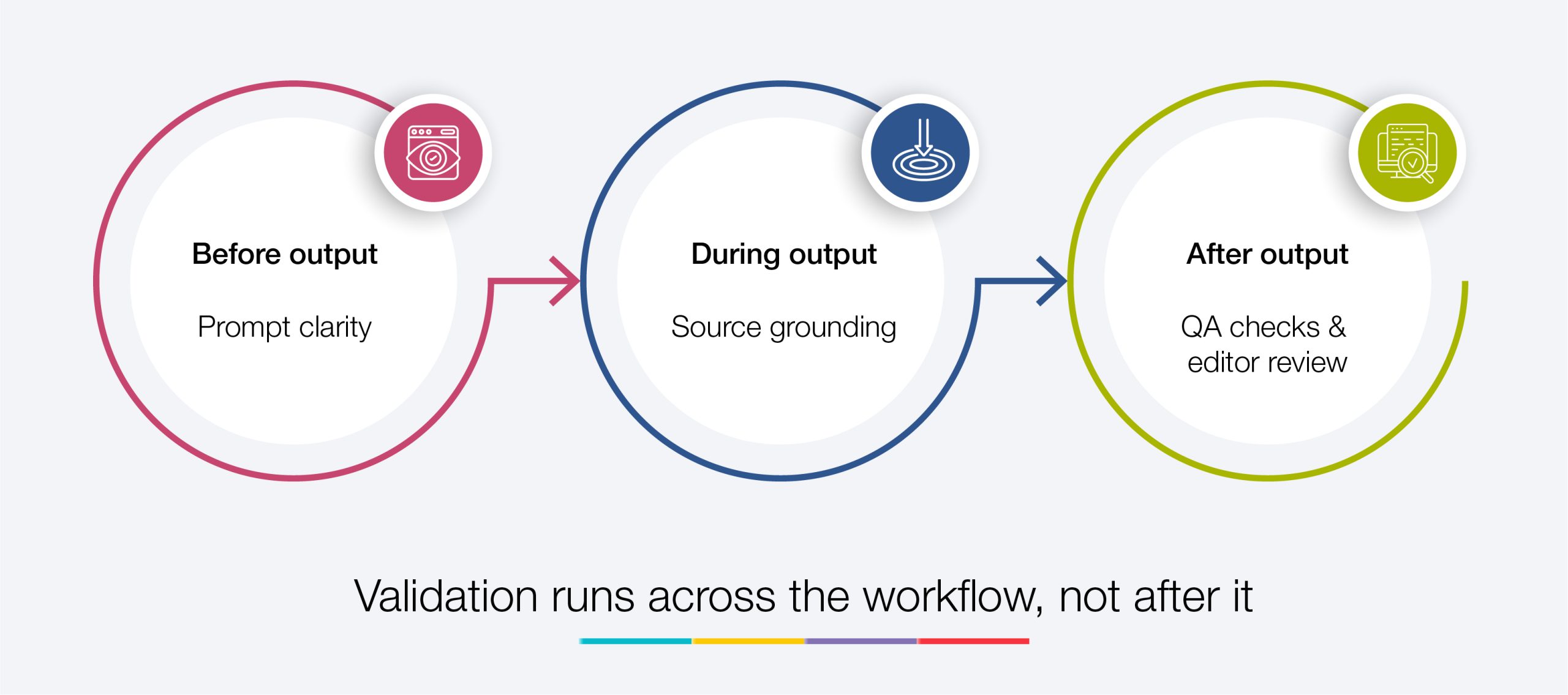
This layered approach reflects how publishing teams are adapting. The goal is not to eliminate variation, but to ensure outputs can withstand scrutiny.
6. The Straive Angle: Domain-Led AI QA for Publishing
Generic QA approaches often fall short in publishing because they do not reflect domain requirements.
Publishing workflows depend on citation accuracy, metadata consistency, and compliance. These are not areas where approximation works.
Straive’s approach is built around this reality. QA is designed within publishing workflows rather than applied externally. Domain expertise shapes validation at every stage.
This enables scalable and reliable QA for AI agents across complex publishing workflows.
This leads to more stable outputs and fewer downstream issues, particularly at scale. Straive’s approach also supports responsible AI publishing by combining domain expertise with robust validation systems.
Exhibit 4. What Makes QA Work in Publishing
This is what separates usable output from production-ready content.
7. Future Outlook: From QA to AI Governance
QA is gradually expanding into governance.
Organizations are defining how AI systems should behave, not just how outputs should be tested. Explainability and traceability are becoming expected. Regulatory attention is increasing.
This evolution reflects a broader shift toward responsible AI publishing, where governance frameworks guide both system behavior and output validation.
In publishing, QA becomes part of system design rather than a final checkpoint.
The focus shifts from testing outputs to managing system behavior over time.
8. Conclusion
AI introduces variability into workflows that were built on predictability.
Traditional QA struggles in this environment.
What replaces it is a set of practices focused on layered validation, broader testing, traceability, and informed human judgment. These evolving AI quality assurance frameworks for publishing enable organizations to balance innovation with trust.
Uncertainty remains.
But it becomes manageable, and that is what allows publishing teams to maintain trust while adopting AI at scale.
Straive helps clients operationalize the data> insights> knowledge> AI value chain. Straive’s clients extend across Financial & Information Services, Insurance, Healthcare & Life Sciences, Scientific Research, EdTech, and Logistics.